Embedding、Embedding、Embedding 到底什麼是 Embedding? 你是否曾經想過,當你在網路上搜尋一些資訊時,背後的運作原理是什麼?答案就在於文字向量化技術。這項強大的工具能夠將文本轉換為向量,讓計算機能夠理解文本的語義含義。LlamaIndex 就是利用這項技術來建立強大的搜索引擎。它使用預訓練的向量化模型,如OpenAI 的 text-embedding-ada-002、BGE Model等,將檔案和查詢轉換為向量。並通過計算向量之間的相似度,快速找到與查詢最相關的文檔。
這項技術不僅應用於搜索,還可用於文本分類、情感分析等各種自然語言處理(NLP)任務。隨著深度學習的發展,Embedding 模型變得越來越強大和精確。今天我們將深入探討 LlamaIndex 中的 Embedding 技術。我們將介紹Embedding 的基本概念、使用方法。讓我們一起探索這個神奇的數字世界吧!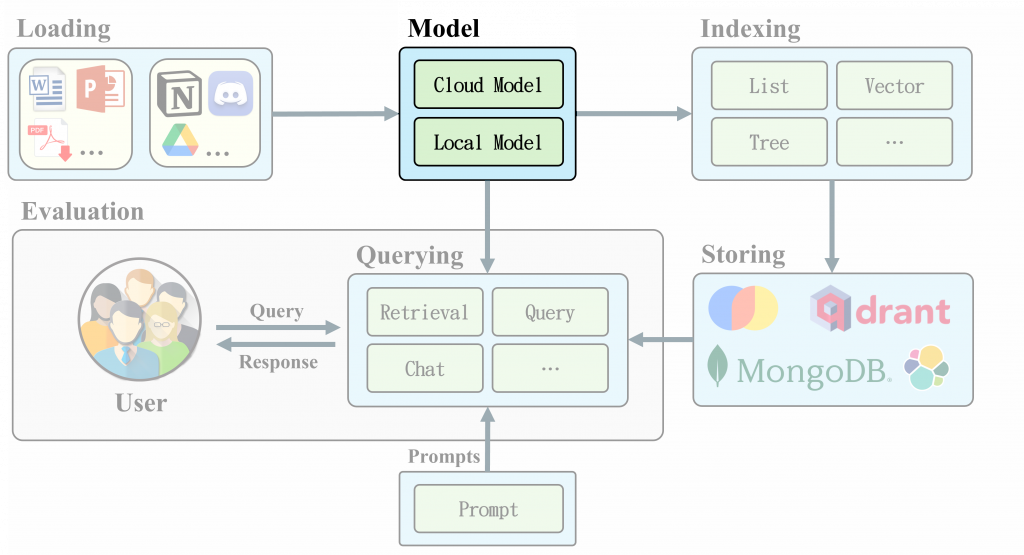
Embedding 的原理是將高維度的離散特徵映射到相對低維的連續向量空間中。每個實體(entity)都被表示為一個向量,向量中的每個元素稱為一個特徵。在自然語言處理中,單詞 Embedding 可以幫助機器學習模型理解單詞之間的關係和含義。 Embedding 讓深度學習模型能更有效地了解語義並同時保留語法關係。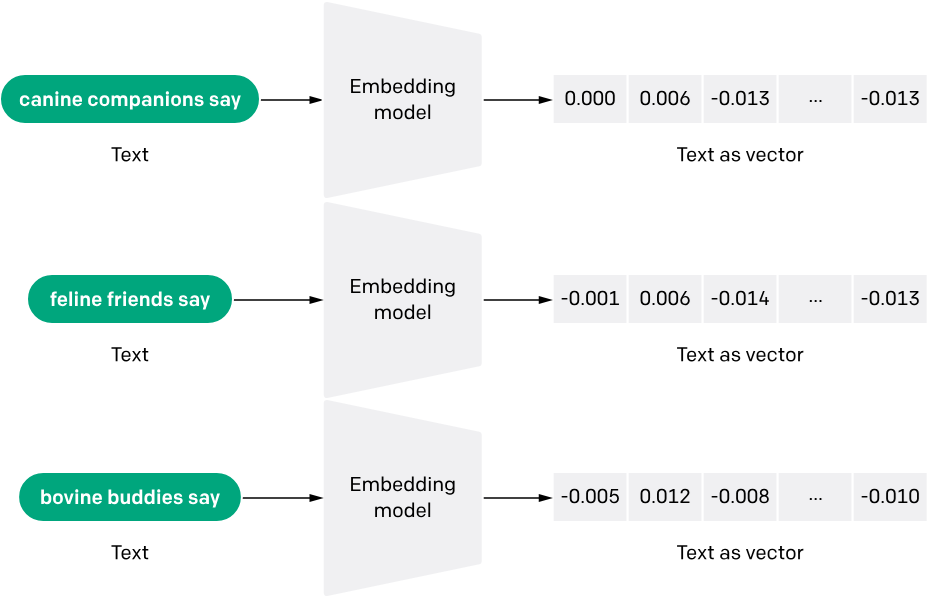
如果我們進一步將 Embedding 結果的高維空間可視化,會發相似的詞彙彼此距離很近,這就是 Embedding 的功能。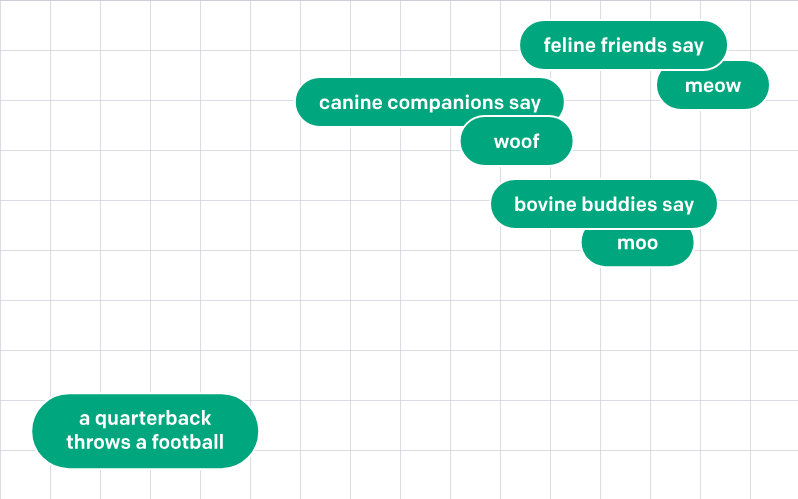
接著我們試著透過 LlamaIndex 實現 Embedding 計算吧~
| 模型名稱 | 輸入長度(Tokens) | 輸出維度 |
|---|---|---|
| text-embedding-ada-002 | 8196 | 1536 |
| text-embedding-3-small | 8196 | 1536 |
| text-embedding-3-large | 8196 | 3072 |
安裝相關依賴pip install llama-index-embeddings-openai
執行以下程式,將會成功將文字轉換成 1536 維度向量
import os
os.environ["OPENAI_API_KEY"] = ""
from llama_index.embeddings.openai import OpenAIEmbedding
embed_model = OpenAIEmbedding()
# embedding
vector = embed_model.get_text_embedding("用50字介紹台灣")
vector
# Output[1]: [0.0017384070670232177, -0.014998571015894413, -0.010654302313923836, -0.00761821074411273, -0.018286503851413727, ..., -0.00017478074005339295, -0.007226456888020039, -0.022861627861857414]
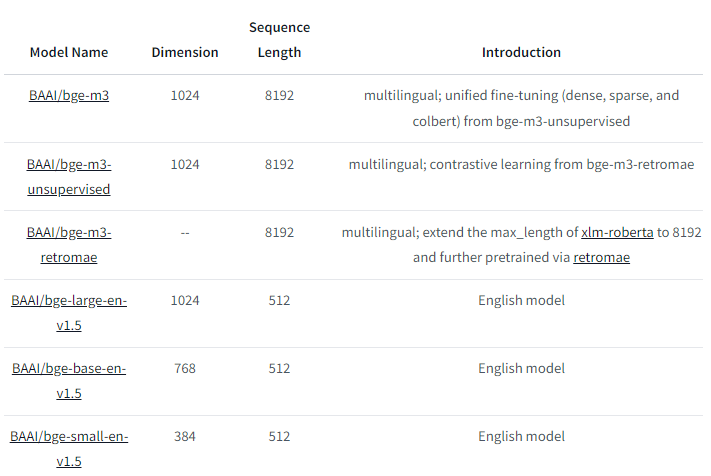
pip install llama-index-embeddings-huggingface
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
# embedding
embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-m3"
)
vector = embed_model.get_text_embedding("用50字介紹台灣")
vector
# Output[1]: [0.009834644384682178, -0.019660603255033493, -0.04171082004904747, -0.016028346493840218, -0.006163890473544598, ..., 0.023633258417248726, 0.01554850209504366, -0.04536805301904678, -0.00365400779992342, -0.02269640564918518]
Embedding 是現代自然語言處理(NLP)的關鍵技術,將文本數據轉換為電腦可以理解的向量,從而讓機器能夠更有效地處理語義和語法。無論是使用 OpenAI 還是 BGE 模型,這些工具都為開發者提供了強大而靈活的解決方案。隨著深度學習的進展,Embedding 的應用將持續拓展,從文本搜索到情感分析,這些技術正逐步改變我們處理和理解語言的方式。通過 LlamaIndex 等平台的整合,使用這些模型變得更加方便,讓AI應用更加智能化與精確化。


 iThome鐵人賽
iThome鐵人賽